Version 1 UUIDis meant for generating time-based UUIDs. They also accept 48 bit long identifier (281,474,976,710,655 available values). In many cases it make sense to use a machine MAC Address as an identifier. Sometimes if we use several UUID generators on the same system, we can just use configured identifiers. It is very important to have unique identifier in a distributed environment. That will guarantee conflict-free ids.
Version 4 UUIDis meant for generating UUIDs from truly-random or pseudo-random numbers. UUID v4 are not giving us guaranteed unique numbers; they are rather practically unique. Probability of getting a duplicate is as follows:
Only after generating 1 billion UUIDs every second for the next 100 years, the probability of creating just one duplicate would be about 50%
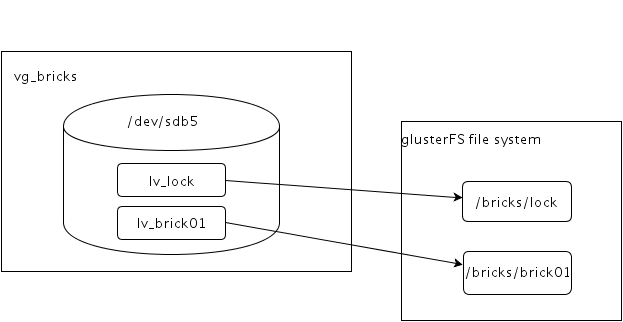
[root@nas1 ~]# lvdisplay
--- Logical volume ---
LV Path /dev/vg_bricks/lv_lock
LV Name lv_lock
VG Name vg_bricks
LV UUID rnRNbZ-QFun-pxvS-AS3f-pvn3-dvCY-h3qXgi
LV Write Access read/write
LV Creation host, time nas1.rickpc, 2014-07-04 16:54:20 +0800
LV Status available
# open 1
LV Size 64.00 MiB
Current LE 16
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:2
--- Logical volume ---
LV Path /dev/vg_bricks/lv_brick01
LV Name lv_brick01
VG Name vg_bricks
LV UUID BwMD2T-YOJi-spM4-aarC-3Yyj-Jfe2-nsecIJ
LV Write Access read/write
LV Creation host, time nas1.rickpc, 2014-07-04 16:56:11 +0800
LV Status available
# open 1
LV Size 1.50 GiB
Current LE 384
Segments 1
Allocation inherit
Read ahead sectors auto
- currently set to 256
Block device 253:3
1.5. 安裝GlusterFS and create volumes
想瞭解CTDB與GlusterFS之間是如何運作以及如何安裝GlusterFS和CTDB, 可參考 GlusterFS/CTDB Integration3 和 Clustered NAS For Everyone Clustering Samba With CTDB4.
Install GlusterFS packages on all nodes
$ wget -nc http://download.gluster.org/pub/gluster/glusterfs/3.5/LATEST/RHEL/glusterfs-epel.repo -O /etc/yum.repos.d/glusterfs-epel.repo
$ yum install -y rpcbind glusterfs-server
$ chkconfig rpcbind on
$ service rpcbind restart
$ service glusterd restart
Do not auto start glusterd with chkconfig. 
Configure cluster and create volumes from gluster01
將 gluster02g 加入可信任的儲存池 (Trusted Stroage Pool)
$ gluster peer probe gluster02g
若遇到 gluster peer probe: failed: Probe returned with unknown errno 107, 請參考5
確認信任關係
gluster peer status
建立 Volume: 在 glusterfs 的架構中,每一個 volume 就代表了單獨的虛擬檔案系統。
$ yum install -y rpcbind nfs-utils
$ chkconfig rpcbind on
$ service rpcbind start
Configure CTDB and Samba only on gluster01
$ mkdir -p /gluster/lock
$ mount -t glusterfs localhost:/lockvol /gluster/lock
Edit /gluster/lock/ctdb
CTDB_PUBLIC_ADDRESSES=/gluster/lock/public_addresses
CTDB_NODES=/etc/ctdb/nodes
# Only when using Samba. Unnecessary for NFS.
CTDB_MANAGES_SAMBA=yes
# some tunables
CTDB_SET_DeterministicIPs=1
CTDB_SET_RecoveryBanPeriod=120
CTDB_SET_KeepaliveInterval=5
CTDB_SET_KeepaliveLimit=5
CTDB_SET_MonitorInterval=15
Edit /gluster/lock/nodes
192.168.3.101
192.168.3.102
Edit /gluster/lock/public_addresses
192.168.18.201/24 eth0
192.168.18.202/24 eth0
Edit /gluster/lock/smb.conf
[global]
workgroup = MYGROUP
server string = Samba Server Version %v
clustering = yes
security = user
passdb backend = tdbsam
[share]
comment = Shared Directories
path = /gluster/vol01
browseable = yes
writable = yes
Set SELinux permissive for smbd_t on all nodes due to the non-standard smb.conf location
$ yum install -y policycoreutils-python
$ semanage permissive -a smbd_t
We'd better set an appropriate seculity context, but there's an open issue for using chcon with GlusterFS.
Create the following script for start/stop services in /usr/local/bin/ctdb_manage
#!/bin/sh
function runcmd {
echo exec on all nodes: $@
ssh gluster01 $@ &
ssh gluster02 $@ &
wait
}
case $1 in
start)
runcmd service glusterd start
sleep 1
runcmd mkdir -p /gluster/lock
runcmd mount -t glusterfs localhost:/lockvol /gluster/lock
runcmd mkdir -p /gluster/vol01
runcmd mount -t glusterfs localhost:/vol01 /gluster/vol01
runcmd service ctdb start
;;
stop)
runcmd service ctdb stop
runcmd umount /gluster/lock
runcmd umount /gluster/vol01
runcmd service glusterd stop
runcmd pkill glusterfs
;;
esac
1.7. Start services
Set samba password and check shared directories via one of floating IP's.
echo off
:LOOP
echo "%time% (^_-) Writing on file in the shared folder...."
echo %time% >> z:/wintest.txt
sleep 2
echo "%time% (-_^) Writing on file in the shared folder...."
echo %time% >> z:/wintest.txt
sleep 2
"12:16:49.59 (-_^) Writing on file in the shared folder...."
"12:16:51.62 (^_-) Writing on file in the shared folder...."
"12:16:53.66 (-_^) Writing on file in the shared folder...."
"12:16:55.70 (^_-) Writing on file in the shared folder...."
"12:16:57.74 (-_^) Writing on file in the shared folder...."
"12:17:41.90 (^_-) Writing on file in the shared folder...."
"12:17:43.92 (-_^) Writing on file in the shared folder...."
"12:17:45.95 (^_-) Writing on file in the shared folder...."
"12:17:48.00 (-_^) Writing on file in the shared folder...."
"12:16:57.74 (-_^) Writing on file in the shared folder...." "12:17:41.90 (^_-) Writing on file in the shared folder...."
紅色兩行的結果, 發現Winodws的連線會有數秒的中斷, 但在數秒後, PC上的test program將重新連上, 符合HA-level recovery